

 Over the last ten years, Prometheus has grown to be the most widely used open source monitoring tool worldwide, giving users the ability to swiftly and simply gather data on their systems. With this facility, users may obtain assistance with their cloud servers and software.
Over the last ten years, Prometheus has grown to be the most widely used open source monitoring tool worldwide, giving users the ability to swiftly and simply gather data on their systems. With this facility, users may obtain assistance with their cloud servers and software.
SoundCloud created the idea for Prometheus after seeing that the metrics and monitoring systems on the market weren’t quite sufficient for their purposes. Prometheus was adopted by the Cloud Native Computing Foundation as their second incubated project after Kubernetes, when it was made available to the general public as free software.
About the Measurements
These measurements are saved as time series data in Prometheus, a free and open-source software. This suggests that timestamps be added to the data so that users may see the metrics at a certain moment in time. For businesses looking to go straight into cloud monitoring, Prometheus is an excellent option since it doesn’t need setup costs, vendor lock-in, or reliance on a single supplier. Because of Prometheus’ smooth interaction with Kubernetes and other native cloud technologies, it is attractive to cloud-native organisations.
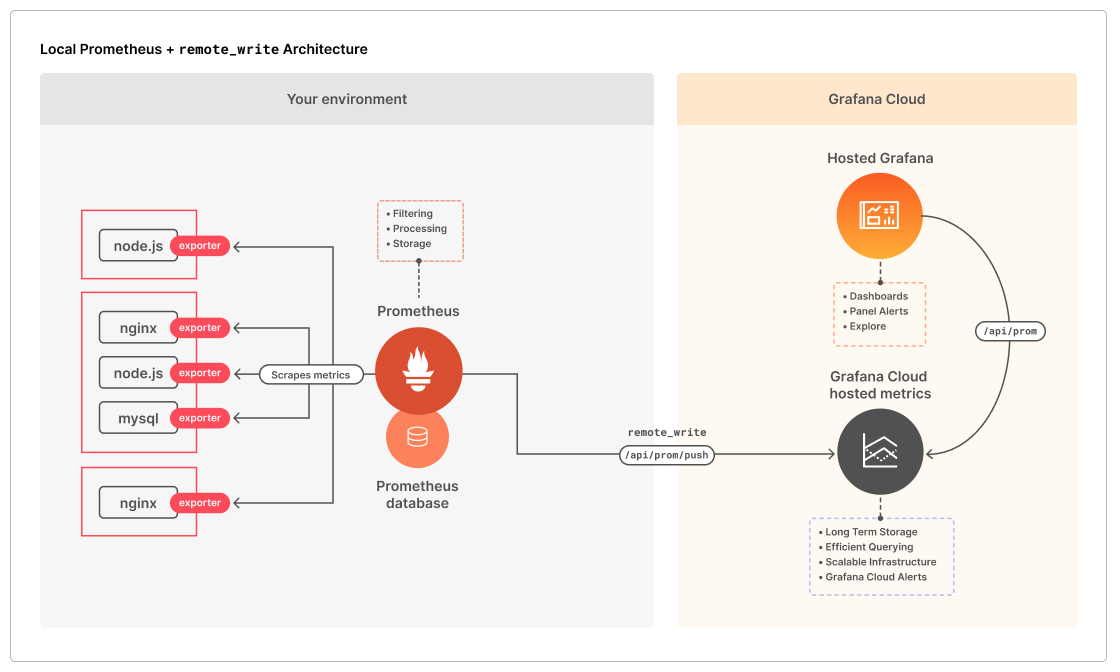
Use of the Metrics
On the other hand, the time needed to use Prometheus for infrastructure monitoring may increase as more data is collected. Because Prometheus is a single-node system, data distribution across several Prometheus servers necessitates complex topologies in order to achieve horizontal scalability. Log and trace data will remain in their respective silos as Prometheus can only gather and store metrics. Engineers won’t be able to swiftly correlate data from various sources as a result, which will hold down incident investigations.
Why is Prometheus metrics important for full-stack observability planning for your systems? We’ll talk about the value of prometheus metrics and how to take full use of them in this post.
What Do the Prometheus Metrics Mean?
Put as simply as possible, metrics are a measurement of everything and everything. Monitoring cloud infrastructure makes heavy use of the metrics that Prometheus collects. The timing and location of any issues will be disclosed by these KPIs.
What the Metrics Say
Metrics obtained from infrastructure monitoring may provide organisations with important information about the condition of a particular environment. The capacity of Prometheus to gather metrics is essential if you want to know as soon as there is an issue with your system. Dashboards may display them graphically, or Prometheus’s AlertManager feature may monitor them and notify users if the data ever exceeds a certain threshold.
Metrics are important because they allow you to monitor system health before users bombard your support staff with enquiries.
The Prometheus infrastructure monitoring system requires targets in order to gather metrics and perform its function. These objectives might be in the form of something that can be measured or they could take another form. Prometheus will gather and store this data from its targets regardless of the circumstances. To identify any problems, these metrics may be compared to other data, such as logs or traces.
Conclusion
A large range of extensions are also supported by the Prometheus client, which may be used to search for and monitor services as well as visualise and export data. The administrator may then choose the instruments that are most suited for the task at hand.